This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.

Maak het onmogelijke mogelijk met GPT en Power Automate
Blog
22 March 2023
Gerrit Jan Hagens
Stel je eens voor: jouw binnenkomende e-mails, documenten en andere ongestructureerde gegevens worden volledig automatisch verwerkt. Ze worden in de juiste context geplaatst en er worden afgebakende vervolgtaken bepaald. Klinkt dat té mooi voor woorden? Met de komst van OpenAI’s GPT in combinatie met Power Automate en de custom Power Platform-connector van Shared kan het.
“Unstructured data is information that is not arranged according to a preset data model or schema, and therefore cannot be stored in a traditional relational database or RDBMS. Text and multimedia are two common types of unstructured content. Many business documents are unstructured, as are email messages, videos, photos, webpages, and audio files.”
Bron: https://www.mongodb.com/unstructured-data
Het probleem van ongestructureerde data
Hoeveel van de informatie waarmee jij werkt valt in de categorie ‘ongestructureerde gegevens’? En heb je wel eens geprobeerd om deze stroom van werk te automatiseren? Het antwoord is vaak het standaardiseren van gegevens. We ontwerpen apps, formulieren en ‘data-rotondes’ om de gegevensstroom af te bakenen. Maar deze oplossingen zijn vaak duur om te ontwikkelen, vergen aanzienlijke schaalgrootte en sluiten niet goed aan op de complexiteit van de praktijk.
GPT lost al onze problemen op!
Met de komst van de GPT-modellen van OpenAI (onder het grotere publiek beter bekend als ‘ChatGPT’), zijn er opeens ontzettend veel nieuwe mogelijkheden te vinden. De technologie is ontzettend gaaf, maar hoe koppel je deze technologie op de juiste manier aan jouw bedrijfsprocessen? Hoe houd je controle op de verwerking en kom je niet voor verrassingen te staan?
Waarom is inzet van GPT op dit onderwerp zo baanbrekend?
Tot eind 2022 maakten we gebruik van herkenning van tekstpatronen (reguliere expressies) of specifieke Machine Learning oplossingen om ongestructureerde gegevens te verwerken.
Enerzijds kregen Reguliere expressies het al lastig wanneer men bijvoorbeeld de mogelijkheid heeft om in talloze vormen een datum en tijdstip te noteren. Anderzijds moesten Machine Learning-oplossingen voor bijvoorbeeld het classificeren van e-mails worden getraind op enorme hoeveelheden voorbeeldgegevens uit een specifieke context. Dit betekent dat men al snel een maatwerk model moet ontwikkelen, wat simpelweg een grote investering is en grote hoeveelheden geschoonde voorbeelddata vereist.
GPT daarentegen is getraind op een codex die zo veelomvattend is dat het de context en verbanden van zo’n beetje alle onderwerpen eerder heeft gezien. Vergelijkbaar dus met hetgeen wij als mensen doen. En dat alles terwijl het verrassend betaalbaar is.
Hoe stuctureer je ongestructureerde data met behulp van GPT?
Simpel, je instrueert het GPT-model om enkel gestructureerd te antwoorden. Hierbij komt het erop aan om de instructie (prompt) strikt genoeg en ondubbelzinnig te formuleren. Je kunt dit op de volgende manieren doen:
- Geef duidelijke instructies welke beslissingen er gemaakt moeten worden of welke zinssnedes je wilt extraheren uit de tekst. Bijv. een tijdstip, een verzoek of namen van andere personen.
- Geef duidelijke instructies hoe de interessante informatie uit punt 1 teruggekoppeld moet worden door GPT zodat een ‘traditioneel’ systeem dit verder kan verwerken. Persoonlijk ben ik er een fan van om het antwoord in zgn. ‘JSON’-formaat op te laten stellen. Zo wordt de informatie in een vaste en betrouwbare vorm teruggegeven voor verdere verwerking.
Zullen we gewoon eens een voorbeeld geven?
Het voorbeeld
Om dit in de praktijk te kunnen gebruiken hebben we een kleine demo opgezet in Power Automate, het Low code automatiseringsplatform van Microsoft.

Zoals je ziet, is een binnenkomende e-mail het begin van het verwerkingsproces. Het proces eindigt met het inplannen van een monteur in het ERP-pakket van de verwerkende partij.
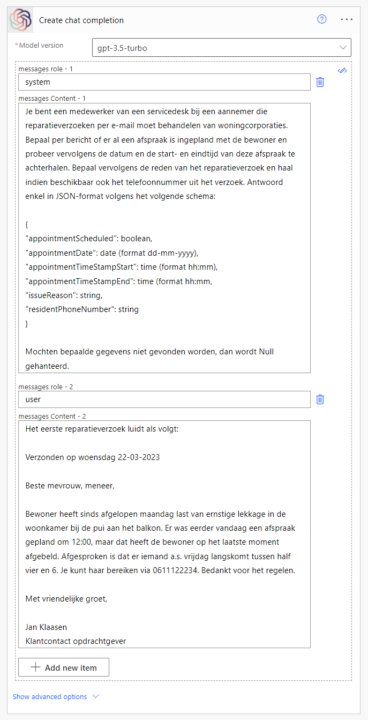
Vervolgens bouwen we de instructie voor GPT op. Om gemakkelijk verbinding te kunnen maken met het GPT 3.5 Turbo-model van OpenAI, gebruiken we hun API via onze eigen Custom connector (zie onze eerdere blog hierover). Laat het ons even weten als je die wilt hebben.
Het model werkt via deze API net iets anders dan ChatGPT, maar is wel grotendeels vergelijkbaar. Het is mogelijk om meerdere chatberichten in één keer te versturen, om zo ook een grotere conversatie mee te sturen. We maken hier onderscheid in drie typen berichten: system-, user- en assistant-berichten:
- System | de initiële instructie die de kern vormt van het gedrag van het GPT-model. Hierin bepaal je de kaders.
- User | de detailering en uiteindelijke opdracht voor GPT die het binnen de gesteld kaders zal uitvoeren.
- Assistant | de reactie van GPT op eerdere opdrachten.
Het resultaat?
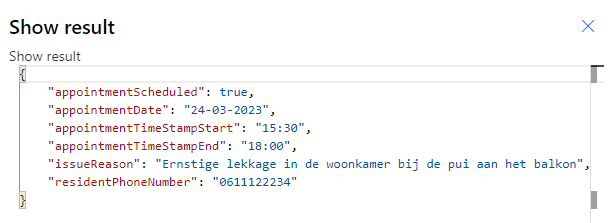
Wanneer we de Power Automate Flow uitvoeren krijgen we het volgende resultaat terug.
Vlekkeloos. Fantastisch toch?!
Waar moet je bij het toepassen op letten?
Er zijn vervolgens diverse verdiepingen die je kunt uitvoeren om dit simpele voorbeeld breder toepasbaarder te maken in complexere scenario’s. We hebben er hieronder een paar uitgangspunten uiteengezet:
- Deel het bepalen van de juiste vervolgacties op in deelproblemen door meerdere instructies op te stellen die de uit te voeren taken verder detailleren en naar elkaar verwijzen.
- Werk bij direct klantcontact op basis van conceptberichten die zijn opgesteld door GPT en vóór verzenden worden gecontroleerd door een ‘human in the loop’. Bij Shared doen we dit bijv. door een kleine app voor deze eindgebruikers neer te zetten of door automatisch concept e-mails aan te maken in de betreffende e-mailpostvakken.
- Vraag GPT om bijvoorbeeld een Confidence interval mee te geven aan het resultaat om zo te bepalen of het antwoord betrouwbaar genoeg is. Dit lijkt wellicht een contradictio in terminis, maar blijkt in de praktijk verrassend bruikbaar.
- Let goed op met de verwerking van evt. persoonsgegevens (zie onder).
Ga zelf aan de slag!
Je kunt hier nu al mee aan de slag. Voor experimenten kun je gemakkelijk GPT tot je beschikking krijgen:
- Direct via OpenAI, en dus buiten de controle van jouw organisatie en op Amerikaanse servers. GPT 3.5 Turbo kun je hier voor $ 0,002 / 750 woorden gebruiken;
- Via Azure OpenAI, en dus binnen de Tenant van de eigen organisatie en Europese servers. Het goedkopere GPT 3.5 Turbo model is hier op het moment van schrijven nog niet beschikbaar (join the waitlist). Het duurdere Davinci-003 kost je $ 0,02 / 750 woorden en kent één prompt zonder de onderverdeling in verschillende typen berichten.
Bij OpenAI is het aanvullend mogelijk om een opt-out aan te vragen voor het gebruik van jouw data bij het trainen van nieuwe modellen.
Bij het leggen van een verbinding met de modellen kun je gebruik maken van de standaard/custom connectoren die worden geboden binnen het Microsoft Power Platform (OpenAI / Azure OpenAI Service). Of als je van de nieuwste modellen binnen OpenAI gebruik wilt maken kun je even contact met ons opnemen voor gebruik van onze eigen Custom connector.
Let op: GDPR / AVG
Zoals hierboven vermeld dien je wel op te passen met het verzenden van persoonsgegevens naar de genoemde GPT services. Naast het hebben van adequate verwerkersverklaringen en expliciete consent, is het o.a. ook zaak om te kiezen voor een dienstverlener waarbij de data op Europese bodem blijft. Hoewel dit is te mitigeren door de persoonsgegevens uit de teksten te verwijderen, is deze klus ironisch genoeg een voorbeeld van het verwerken van ‘ongestructureerde data’ waar automatisch systemen juist zo’n moeite mee hebben.
Tot slot
Zo, nu weet je hoe we dat doen. Slaat jouw brein ook al op hol van alle mogelijke toepassingen binnen jouw organisatie? Mooi! Met bovenstaande stappen heb je als het goed is een aardig idee gekregen van de aanpak. Nu moet je dus zelf aan de slag als ‘aanjager van vooruitgang’!
Ben je enthousiast geworden maar weet je eigenlijk nog steeds niet waar je moet beginnen? Laat het ons even weten, dan zetten we er samen onze schouders onder!